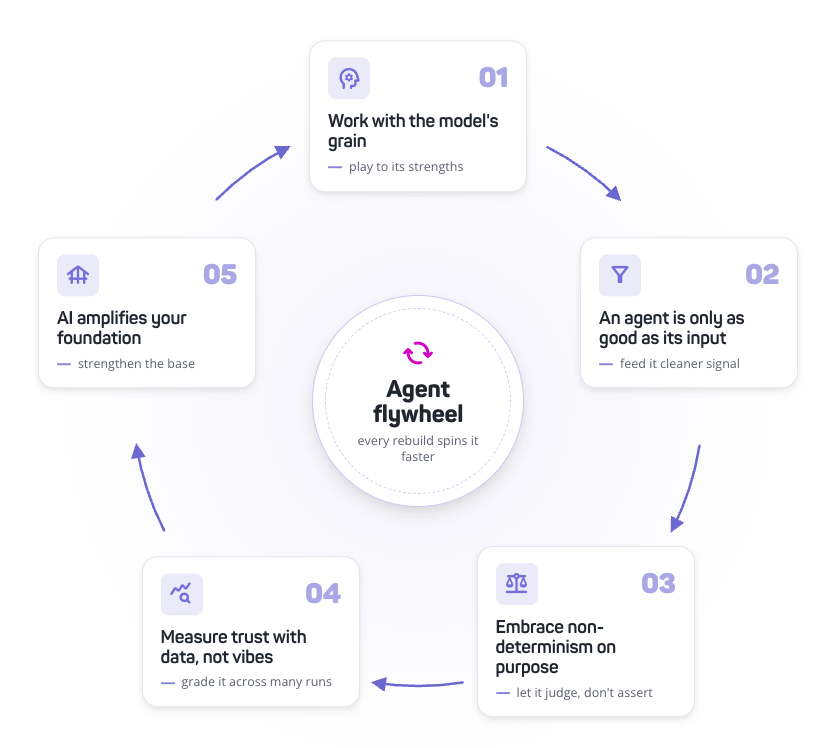
Over the last few years we've rebuilt our test-authoring agent five times. In normal software, rewriting a core feature that many times is a flashing red light; when the models shift under you every few months, it's mostly just what staying current costs. The useful part is what survived every rewrite — five things that held no matter which model we were running on.
Work with the model's grain, not against it. Back in 2023 I tried to get PaLM to pick the single most similar word to a target in the DOM, for smarter auto-healing. It failed every way I framed it — but the outputs showed it clearly understood the task. It was bad at picking one similar word and surprisingly good at grouping words by meaning. So we rebuilt auto-healing around semantic grouping instead of arguing with it, and a hard limitation turned into a reliable feature. These models have a grain, like people do; you get further shaping the system around what they're already good at.
An agent is only as good as its input. Most of the agent failures I've chased turned out to be upstream of the model — a planning session stuffed with base64 screenshots the model can't read, a tool returning a vague error the agent couldn't act on, the right context buried under noise. The model usually wasn't the problem; the signal we handed it was. We've gotten far more mileage out of cleaning up what goes in — tighter tool definitions, scoped context, error messages written for the model to actually use — than out of swapping the model itself.
Embrace non-determinism on purpose. Testing is supposed to remove uncertainty, so deliberately putting a probabilistic model in the middle of it felt like a category error. It wasn't. When we leaned into letting a model judge whether an application state was right — in plain language, the way a person would — it expanded what automated testing could even cover. The trick was using the model where judgment beats a brittle assertion, not everywhere.
Measure trust with data, not vibes. For a while we tested our AI features with small hand-curated sets and spot-checks, and it left us blind to silent regressions. The fix was building evaluator suites — the same judge idea, pointed inward — that grade our agents across many runs. That's how we caught a regression hiding inside an upgrade: moving to Gemini 3 cut reasoning loops by something like 2–4x, but the same report flagged hardcoded values going up, because the model was now finishing harder tests that older ones gave up on. I'd never have spotted that by eye.
AI amplifies whatever foundation you've built. When we scaled coding agents across our repos this year, the biggest thing slowing them down wasn't the AI — it was build times, shaky CI, thin test coverage. The same fundamentals that slow people down. Fixing them helped the agents and the humans in equal measure. A non-deterministic tool doesn't make error handling, reusability, and tests matter less; it runs your weak spots over and over until they show.
What strikes me looking back is how little of this was about the model getting smarter. In 2023 we couldn't get a model through a login screen; today the model is rarely the bottleneck. The harder questions now are fit and cost — whether an agent has the context about what you care about, works inside the tools you already use, and earns its keep on latency and token spend instead of taxing the team. The bar I keep coming back to is whether it behaves like a good teammate.
I had a handful of PRs open at the same time last week, and the bottleneck wasn't the code — it was me remembering what each session was doing by the time I came back to it. You can't keep a chat window open for every PR. So I wrote a small skill: save dumps the current session to a file keyed by a pull request, and load brings it back when I return to that PR. If one piece of work spans three repos, it's stored once and I can reload it by any of the three PR numbers. When every PR in a memory gets merged, it quietly deletes itself in the background — I'm not going to garbage-collect my own notes. The whole store is local and gitignored, because this is my mess to keep, not the team's.
I've been in a lot of discussions lately about independent testing agents, why you'd want one separate from your coding agent, and what makes it different. It isn't really about the model. Part of why coding agents feel so autonomous is that the verification problem was mostly solved for them. They inherit compilers, linters, test runners, CI, source control. Structured feedback that tells them, precisely, whether they're right or wrong. The model is impressive, but it's standing on decades of verification infrastructure it never had to build.
An independent testing agent inherits almost none of that. What it acts on isn't source code, it's a running app: non-deterministic, stateful, changing under it, and nothing volunteers whether it succeeded. There's also a reason you want it independent. A coding agent checking its own work is grading its own homework. You want a separate agent whose only job is deciding whether the product behaves. So its harness has to be built from scratch, and I've been working out what's actually in it.
Start with acting. A testing agent has to do what a user does. It clicks through a web app, taps through a mobile app, calls an API, so the harness has to give it real hands on the product across every surface customers use. But that part is getting commoditized. Any capable model can drive a UI or hit an endpoint now. Executing a test isn't the hard problem anymore.
The hard problem is verification. How does the agent know a login actually worked, a checkout actually completed, a page rendered the way it should? Generating the action is easy-ish; deciding whether the result was right is the whole job. Without a verification layer you haven't built an autonomous tester. You've built an autonomous clicker.
Verification starts with observing, deeply, the way a user would and a tester would. The agent needs screenshots, DOM state, network activity, logs, traces, the runtime behavior. But collecting evidence isn't enough. The harness has to compare what it saw against what was expected and decide whether the behavior was correct, and that judgment is the hard, valuable part.
It also has to do that efficiently. Easy to wave away until you run it at scale. The naive version, where you hand the whole DOM, every screenshot, and all the network traffic to the model on every step and ask "did that look right?", costs enormous tokens and time for one verdict. A good harness runs the cheap deterministic checks deterministically, saves the model for the judgments that need it, and uses what it already knows about the app so it isn't reasoning from raw pixels each run. At the scale a real suite runs, that's the difference between viable and not.
And verification compounds. Every run produces knowledge: which selectors are stable, which flows matter, which failures are expected, which recoveries work. A real harness keeps that and hands it to the next run. Without it, the agent shows up as a brand-new tester every time it opens the browser. It's most of why pointing a general-purpose agent at a browser only gets you so far.
And none of it matters unless people trust the verdict. The agent touches credentials, environments, and real data, so it has to run inside the same controls a person would, and explain itself: what it did, why it decided what it decided, what it saw and concluded. The harness isn't only constraining the agent; it's making its work auditable.
So here's where I've landed. Coding agents got a head start because software already had a verification harness. Compilers, tests, CI, and version control all tell an agent when it's right and wrong. Testing doesn't come with one, so it has to be built. And the hard part was never getting the agent to act. It's getting it to know what happened, judge whether it was right without spending a fortune to do it, and leave behind evidence the rest of us can trust.
I've been thinking about how LLM coding costs scale across the life of a project, and I'm not sure the way we usually frame it holds up. Greenfield is where the velocity multiplier looks the best — small context, clean abstractions, low blast radius — and that's also where the per-change token cost is lowest. Both of those move in the wrong direction as the codebase gets bigger and harder to reason about. Each change pulls in more files, more constraints, and more historical decisions the model has to re-discover. The bill goes up while the speedup goes down. I'm guessing this gets worse on projects built primarily by LLMs, because the patterns the model laid down in the easy phase don't always hold up under the weight of real product complexity, and the inefficiencies are harder to spot when nobody hand-wrote them. That's a hunch, not a finding — I'd want to see real cost-per-feature curves on a few projects of comparable scope before I'd commit to it. But it's the question I keep coming back to when people quote a velocity multiplier without saying what month they measured it in.
I noticed Claude was building a lot of things I wasn't sure I wanted built yet. The pattern was always the same: I'd type something like "can we make X do Y?" and come back to a plan, a diff, and sometimes a PR description. Which is fine when "can we" really means "do it" — and a problem when I was still figuring out if it was the right move.
So I added a rule to my CLAUDE.md. If a prompt sounds like a suggestion or an open question — "let's do X", "what if we tried Y?", "should we Z?" — Claude has to push back first. Is this the right problem to solve? Is there a simpler approach? What's the downside? Only after I confirm does the model get to write code. Imperative phrasing — "add X", "fix Y", "implement Z" — still goes straight to work.
The first time it triggered I almost edited the rule back out, because the critique was annoying. Then I realized that was the point. I'd been paying for code I hadn't really asked for.
A failed click, then a compaction event, then a pivot to a completely different strategy. That sequence is what I keep coming back to from a recent agent session. The compaction had run between the failure and the next decision, and by the time the model picked back up, the most relevant context for the choice in front of it — "the click I just tried didn't work" — had been summarized away.
The summary itself was reasonable. What's wrong, I think, is the timing. Compaction immediately after a failed tool call is the worst moment to do it, because the model is about to make a recovery choice and the failure that just happened is the most load-bearing thing in its context. I'm going to try gating compaction on tool-call health: block it right after a failure unless we're at the hard ceiling, and at the soft threshold, require a couple of clean calls in a row before letting it run.
Every time I share a Claude challenge and someone says it behaves fine for them, I wonder what's in their auto-memory that isn't in mine. The memory store captures plenty of team-useful stuff during normal sessions — build gotchas, tool quirks, hard-won corrections — but it's per-engineer and private by default. Everyone's quietly accumulating their own slice of how this codebase actually works.
I wrote a skill that walks my auto-memory, classifies each entry as personal vs team-promotable, greps the existing rules to skip duplicates, and proposes targeted edits to the right destination — a cross-repo rule, a child repo's CLAUDE.md, or a skill's references. Started by running it on my own store to dogfood, got five real promotions plus one conflict it correctly refused to paper over: a memory said "don't put ticket IDs in test names" while our test-writing rules currently recommend the opposite. Surfaced for me to resolve instead of guessing.
I spent some of this morning digging into a slow customer test authoring session, and the issue turned out to be upstream of the agent. The planning conversation had been getting stuffed with everything we'd captured from the original test — including a stack of base64-encoded screenshots we were handing to a model that can't actually read them. Honestly, fair enough that it took its time picking out the things that actually mattered.
It's tempting to feed an agentic tool everything you have and let it figure out what's relevant, but in my experience the signal gets harder to find as the noise piles up. I'd rather scrub input upstream of our agents — early and often — than ask the model to do it for me.
I've been running into a sharp edge with MCP. The protocol is fine for small, structured tool calls, but it doesn't have a clean answer for "here's a large file, operate on it." Most of our test specs never trip this. The ones from larger customers do — handing them through a tool result floods context before the agent has done anything useful.
The available mechanisms are all clunky. Pagination through the spec. A resource the agent has to remember to fetch in slices. A tool that returns a path and lets the agent navigate the file in chunks. Each one works in isolation but adds choreography the agent gets wrong intermittently.
My guess is we end up working around it by doing upload and download by reference — the agent passes a handle to the spec rather than the contents, and operations happen server-side. Not at the protocol layer, just outside of it. We'll see.
We hit a wave of 400s on Gemini 2.5 yesterday that turned out to be a useful kick. The short version is that in required tool-calling mode, Gemini 2.5 has trouble with the size of our test authoring agent's tool library, where Gemini 3.1 doesn't. The fix is to switch to a less strict mode, which is mostly what I'm doing — but it isn't a free flip. With required mode we've been quietly assuming the model always responds with a tool call, and the looser mode means it sometimes won't, which today would corrupt the generation session. So the fix carries its own risk that I have to handle deliberately.
The bigger thing is that the strictness of the tool-calling mode and the size of the tool library both have real costs, and they compound. Each new tool widens the state space the model has to compile in required mode, and it widens the assumptions our own session loop has to maintain. None of that was visible until yesterday — and it's easy to keep adding "just one more" tool, or to leave the mode set to required, when each addition feels small. I think we need to be more intentional about how we configure our agents — both which tools earn a slot, and what we're asking the model to commit to in return. Some of those tools could probably be lazy-loaded the way our skill instructions already are.
Many of us have been struggling with rate limits lately. I spent part of last weekend thinking about why, and realized something embarrassing: I was using the agent to fix merge conflicts and bump a CLI version into the execution engine. That's not what the agent is for. The honest reason I kept doing it — I had roughly 20 worktrees open and couldn't tell you where the code in terminal five actually lived.
I scaled back to four. Named wt1 through wt4, multi-purpose — I decide what each one is for. They share the same color across my terminal, Chrome tab groups, VSCode, and Finder. Each tab gets a Planner session for feature design, a Terminal for deterministic tasks, and one panel per repo.
I know sub-agents could do something similar. But this is more transparent to me — and a CLI task inside a UI session eats context window, while a UI session in a CLI shell doesn't have the right skills loaded. First day. Maybe it helps someone else too.