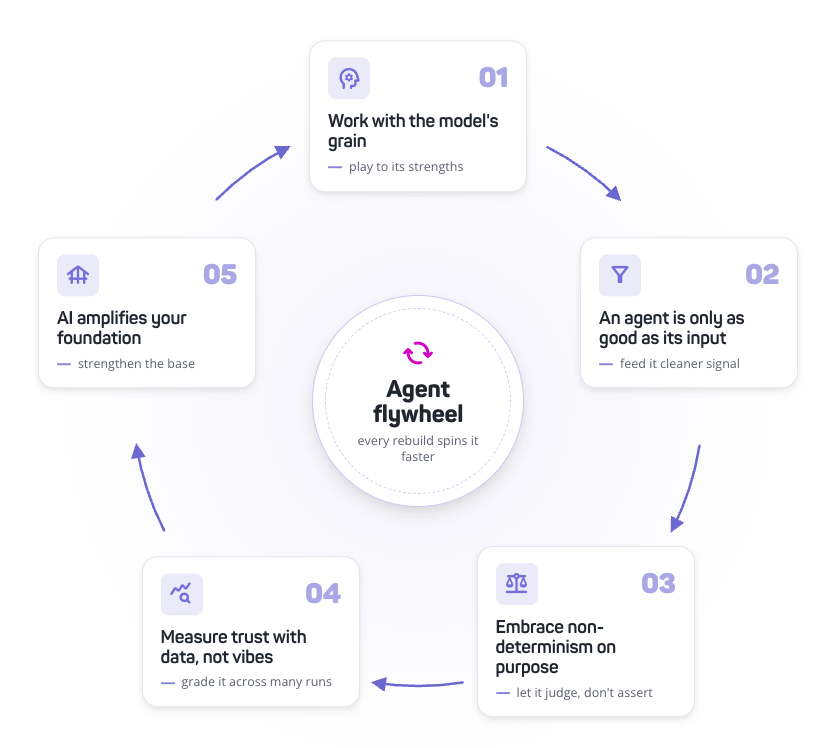
Wiring /codex-review across 16 repos so we stop reviewing every PR.
At our current PR throughput, I'm going to burn out on reviews alone, never mind actual work. We can't move at this pace while also having a human read every change. The model I want us to move toward: ask for human review when you're truly unsure about something, and let the agent reviewers handle the rest.
The piece I shipped to make this real was getting /codex-review wired up across every repo as an on-demand second opinion. Different model family from Claude, uncorrelated blind spots, one comment away when you want it. The work was sixteen PRs across sixteen repos to enable the GitHub Actions trigger, plus a change to our shared workflows repo to make it a first-class slash command. The conceptual work was harder: deciding that "two agent reviews and a human glance" is now an acceptable pre-merge state for routine changes, and reserving real human attention for the changes that genuinely need it. We're not all the way there. But the trajectory is clear, and I'd rather build the routing now than burn out catching up to it later.
The piece I shipped to make this real was getting /codex-review wired up across every repo as an on-demand second opinion. Different model family from Claude, uncorrelated blind spots, one comment away when you want it. The work was sixteen PRs across sixteen repos to enable the GitHub Actions trigger, plus a change to our shared workflows repo to make it a first-class slash command. The conceptual work was harder: deciding that "two agent reviews and a human glance" is now an acceptable pre-merge state for routine changes, and reserving real human attention for the changes that genuinely need it. We're not all the way there. But the trajectory is clear, and I'd rather build the routing now than burn out catching up to it later.